Meta
Meta announces Llama 3 large language models with new performance

Meta has announced Llama 3 open-source large language model (LLM). It comprises two new LLMs with 8 billion and 70 billion parameters designed for different use cases.
Llama 3 has a standard decoder-only transformer architecture and it focuses on improved performance. These new models bring a tokenizer and 128K tokens to encode language efficiently.
New grouped query attention (GQA) helps to achieve inference efficiency on 8B and 70B model sizes. The company says it has tested these models on the sequence of 8,192 tokens using the mask.
Performance:
These new models are the pinnacle of the Llama family at 8B and 70B scales. The company has made improvements to its pertaining and post-training scenarios.
It has reduced false refusal rates in post-training procedures while improving alignment, and responses. The models saw improvements in reasoning, code generation, and instructions following.
Here are the results for the instruct model performance:
8B Model:
- 68.4 on the MMLU 5-shot test
- 34.2 on GPQA 0-shot test
- 62.2 on HumanEval 0-shot test
- 79.6 on GSM-8K 8-shot, CoT
- 30.0 on MATH 4-shot, CoT
70B Model:
- 82.0 on the MMLU 5-shot test
- 39.5 on GPQA 0-shot test
- 81.7 on HumanEval 0-shot test
- 93.0 on GSM-8K 8-shot, CoT
- 50.4 on MATH 4-shot, CoT

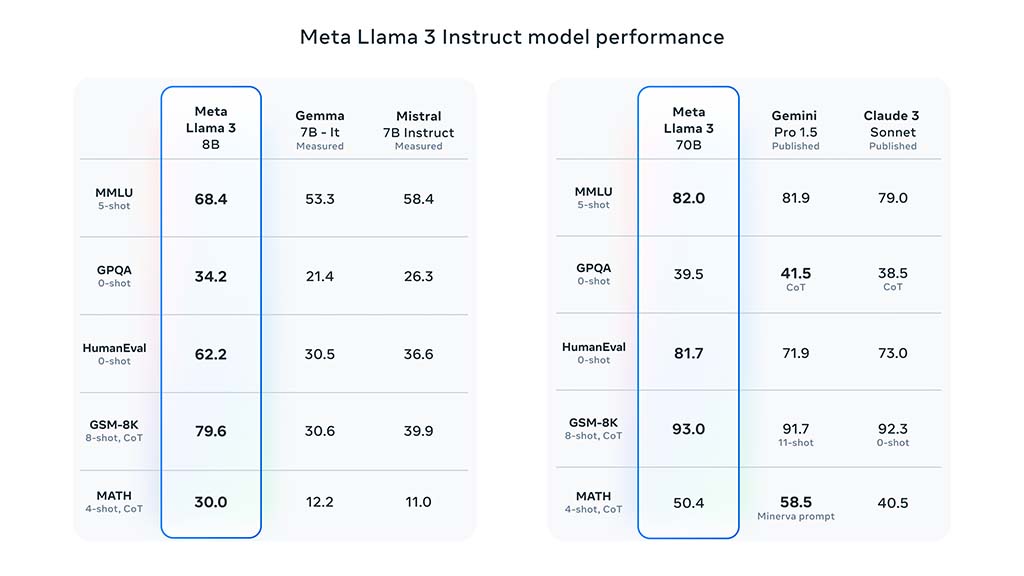
Meta Llama 3 Instruct Model Performance (Source – Meta)
These two models have optimized performance for real-world scenarios with a new high-quality human evaluation set.
The evaluation consists of 1,800 prompts, covering 12 key use cases including asking or advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization.
Performance for pre-trained LLM models:
8B Model:
- 66.6 on the MMLU 5-shot test
- 45.9 on GPQA 0-shot test
- 61.1 on HumanEval 0-shot test
- 78.6 on GSM-8K 8-shot, CoT
- 58.4 on MATH 4-shot, CoT
70B Model:
- 79.5 on the MMLU 5-shot test
- 63.0 on GPQA 0-shot test
- 81.3 on HumanEval 0-shot test
- 93.0 on GSM-8K 8-shot, CoT
- 79.7 on MATH 4-shot, CoT
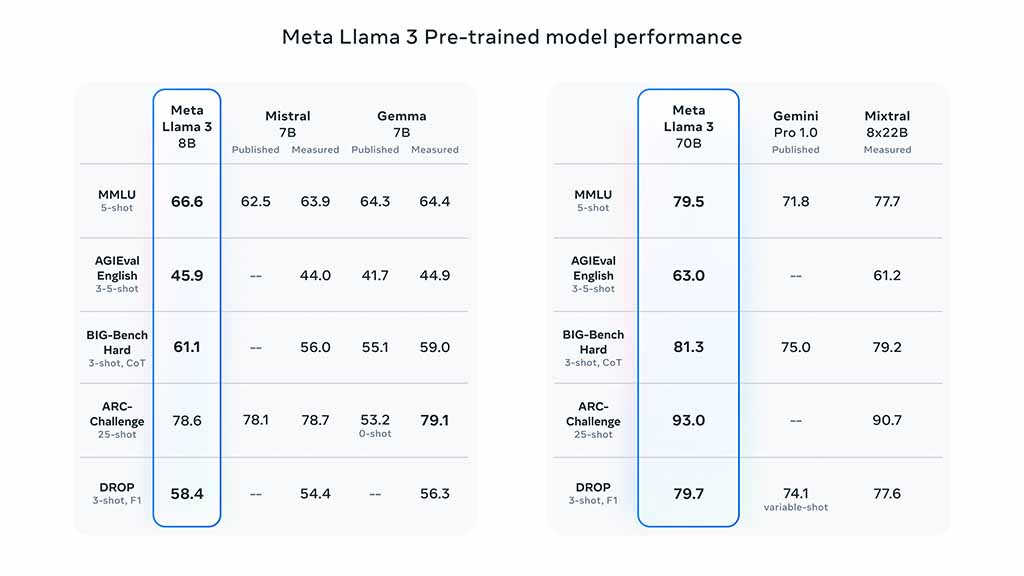
Meta Llama 3 Pre-trained Model Performance (Source – Meta)
More improvements:
These new LLMs will see new capabilities, longer context windows, new model sizes, and better performance in the coming months. The new model sizes are not confirmed at the moment.
Availability:
Llama 3 models will be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake. It is supported by the technologies supplied by AMD, AWS, Dell, Intell, NVIDIA, and Qualcomm.
You can read more information about the new Llama 3 models here on the official site.