xAI
xAI introduces RealWorldQA benchmark to evaluate spatial understanding of multimodal models

Artificial Intelligence (AI) firm xAI has launched RealWorldQA, a new benchmark platform to evaluate basic real-world spatial understanding capabilities of multimodal models.
Large Language Models (LLMs) work on the text-to-text framework and lack an understanding of spatial relationships. Multimodel models on the other hand are key to unlocking spatial understanding.
Unlike LLMs, multimodal models can process different types of data alongside text.
For example, an image with the caption “passengers in the car” allows the model to connect the written word “in” with the visual relationship between the passengers and the car. Multimodal models can go further and understand the size, position, distance, directions, depth, and other relationships.
The RealWorldQA is designed to test these multimodal model capabilities. The initial release of the benchmark consists of over 700 images, with questions and verifiable answers for each image.
The dataset consists of anonymized photographs taken from vehicles alongside other real-world images. xAI says it will improve the benchmark data alongside the improvements released with Grok 1.5 Vision.
The RealWorldQA is available to download from the official xAI site under a Creative Commons BY-ND 4.0 license. The license enables copy and redistribution of the material in any medium or format for any purpose including commercial purposes.
The company shared some samples of how the benchmark evaluates the Multimodal model’s spatial understanding.

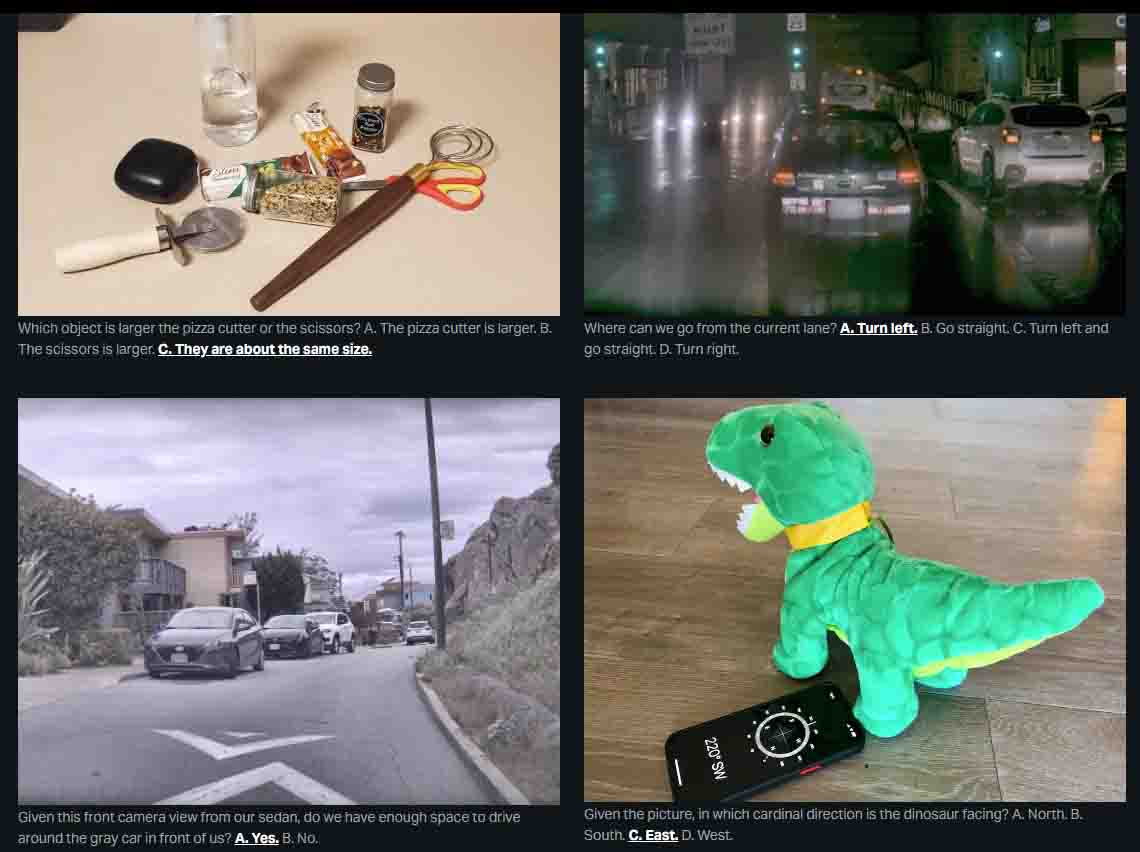
xAI’s RealWorldQA Benchmarking Multimodal Models (Image Credit: xAI)